Last week, the WA Mega Data Cluster ran an event “Big Data for Biodiversity”, which had a range of speakers talking about this topic – which is obviously very dear to our hearts here at Gaia Resources.
After our WA Chief Scientist, Peter Klinken, launched the event (with a great display of his understanding of the Noongar language!) we heard about the WA Data Science Innovation Hub from Liz Dallimore. Based at Curtin Uni, this new Innovation Hub aims to enable data science capabilities to flourish in WA, for “jobs and growth”.
The two presentations after that came from Greg Terrill, Chief Data Officer at the federal Department of Energy and Environment (DEE) Environmental Resources Information Network (ERIN), and from Matt Judkins, a partner at Deloitte. These two really got me thinking…
One of the slides that Greg presented was on his five big things he wanted to see happen:

These were (and hopefully I got these right, as it’s hard to take notes while standing):
- Self-service – empowering people to be able to find out more information about biodiversity much more easily,
- Standards – making sure that the various biodiversity projects could be interoperable,
- Historical information – a key baseline to start from to do things like detect change in environments,
- Economics drivers – looking at how many indices are out there for predicting the economy, so where are the biodiversity and environmental predictors?, and
- Artificial intelligence/machine learning – a key to unlocking more information, and to identify patterns and the like from existing data.
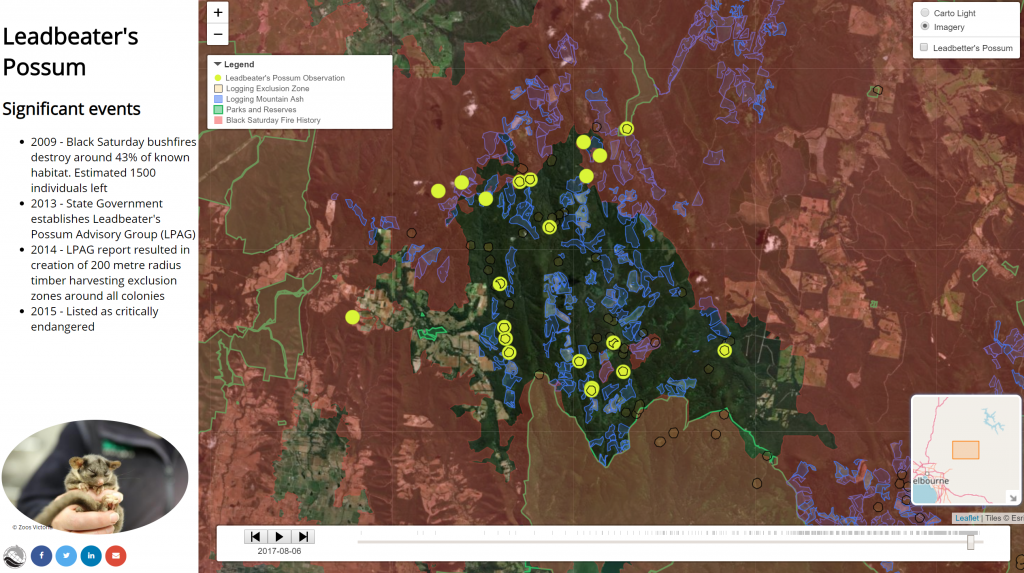
These were really good points to raise, and ones that I’d been discussing earlier in the week with a group of stakeholders around the concept of a new Biodiversity Information Office for Western Australia (more on that some other time). I also got the chance to talk to Greg and his team a little during the week about some of the analytical work we’ve been doing, like our historical Leadbetter’s possum R&D project (see the image below, and click on it for an interactive map).
Matt’s talk was interesting and from a really different point of view. His talk outlined the fact that you needed to talk about metrics on biodiversity in ways that the decision makers will understand, which usually means dollar values. Of course, that does cause some tension straight away, as it is often a struggle to put a dollar value on the conservation of areas, or the provision of natural spaces, and other areas. But if you are facing a stakeholder audience that is driven by dollars, then you need to find ways to convert the environmental factors to that measure – which is often very difficult to do!
One of the things I’ve been thinking through over the years is about somehow codifying the value of biodiversity through the value of the data that you have collected. Data that is used within a biodiversity survey (e.g. a fauna and flora combined survey) costs a lot of money to collect, when you consider the mobilisation of field teams, the expertise that you need to have on hand (e.g. for the specimen identification) and other costs. So perhaps one day, data will be able to be put onto an accounting balance sheet, and maybe even depreciated over time.
It was really interesting – and timely – to talk about big data and biodiversity with such a diverse group of people. At Gaia Resources, we’re always looking for the next challenge and the evolutionary path we need to follow, and big data, analytics and even machine learning are all things that we’ve been looking at for some time.
It won’t be long until we are using many of Greg’s five areas on a daily basis, at least in the areas of environmental technology. I can’t wait – it feels like it’s about time!
Piers
An excellent summary Piers. And environmental practitioners need a lot of help and support to use data to show the community what it will take to conserve our natural environment. ..cos I think the bean counters are winning at the moment.
Thanks Andrew! It was quite an interesting event and sparked a few thoughts for me about how we explain “what it will take” – for another blog sometime, though.