Back in December I wrote about some presentations that I did for the Indo-Pacific Centre for Health Security, and mentioned that one of the points that I raised to the attendees was about data standards.
At Gaia Resources we’ve been heavily involved in data standards since the early days of the company (and before, in some cases!). Personally, I have been involved in the reviews of standards like the TDWG Access Protocol for Information Retrieval (TAPIR), and have implemented toolkits to deliver data in the Darwin Core exchange standard. In previous roles representing Museums I’ve also worked on standards approaches with the Faunal Collections Informatics Group, that supports the Council of the Heads of Australian Faunal Collections.
Alex has a similar background, except from the botanical side. He’s been involved in the technical groups around the Council of the Heads of Australasian Herbaria, specifically with the Herbarium Information Systems Committee that developed the national herbarium specimen data exchange standard HISPID, and was for six years the Oceania representative in the international working group Biodiversity Information Standards (TDWG). Along the way, we’ve all seen and used a range of data standards, unique identifier approaches, metadata standards, exchange standards – and had a lot of hair pulling (we”, metaphorically in my case).
But, why do you need data standards? Let’s look at an example, using something we know pretty well.
In the states of Western Australia and Victoria, where we have implemented the Atlas of Environmental Health. This has become a de facto data standard for this aspect of the Environmental Health domain. The Atlas is made freely available to all Local Government Authorities to use in those states through the Departments of Health and Health and Human Services respectively, and this was the first time that a state-wide picture of mosquito trapping results could be implemented without significant data collation efforts. With a few clicks, you can generate a current map of mosquito populations, like this one we have shown many times before for Victoria:
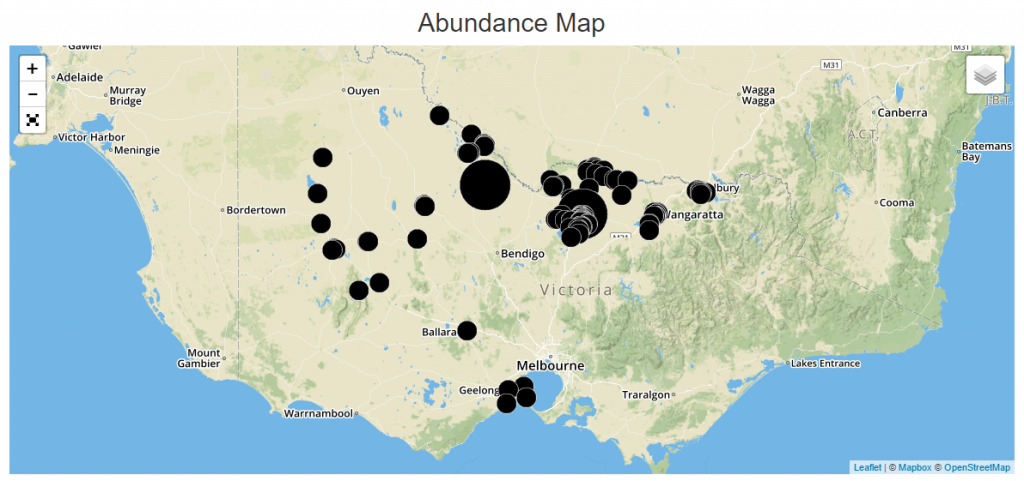
This map (in the system, not this one above) is dynamic, and so it is constantly up to date with the latest population information. Right now, to do this for the whole country, you’d have to do the following:
- know what you are looking for (e.g. the size of mosquito populations across Australia),
- extract the data from each of the States from their own systems (some use Access databases, others commercial software, or the Atlas, or other tools),
- undertake an exercise that would look across all of the datasets that have been provided, and work out which fields are the same (the ones containing the coordinates of the observations, species names, dates and abundance figures – which hopefully are all contained in all datasets),
- migrate the data into a single data store, working through things like blanks, spelling mistakes, outdated taxonomy, different coordinate reference systems, etc, and
- then pull this data into a spatial system of some sorts to draw the map shown above.
Frankly, by the time this is done manually – which could take weeks – the information will be so out of date it will be next to useless. However, if the three data standards above were implemented the process would be:
- all jurisdictions extract the data from their systems (which are compliant with the data standards) into the data exchange standard, which is provided with metadata in accordance to the standard,
- the data is ingested into a new data store (and since all are compliant with the data exchange standard, this is much simpler), with some quality control implemented (still looking at the blanks, spelling mistakes, etc), and
- the data is pulled out into a spatial system for mapping.
This second eventuality should take a matter of minutes to do, assuming that everyone is compliant with the standards. When groups like the Indo-Pacific Centre for Health Security, or the National Arbovirus and Malaria Advisory Committee meet up they look at these sorts of reports for each State in paper or digital forms, so there’s a lot of different ways in which that data is presented (we’ve presented at NAMAC once before on the Atlas of Environmental Health).
So, how can we improve on this situation? I’m always fired up when solving interesting problems and as a result I’ve been sketching out ideas on various notebooks while I’ve been researching the area of data standards in the Environmental Health field since late last year, so here’s my take on a way forward.
Firstly, if we were starting from scratch here, what sort of data standards do we need? At the very least, there should be three data standards developed for the Environmental Health area, namely:
- Metadata standards – standards that we can use to describe the data itself (e.g. this data contains information about mosquito monitoring, ranges from this date to that date, covering the state of Western Australia, etc)
- Data standards – the standard set of fields that we can use in describing the data itself (e.g. using unique identifiers, fields for genus, species, date trapped, time trapped, number of individuals, the weather conditions, controlled vocabularies, etc), and
- Data exchange standards – a set of fields that can be used in a data extract so that when this data is provided from one group to another it can be readily ingested and used (e.g. genus and species as a single field, date trapped, viruses present, etc).
It’s more than likely there would be many extensions to each, both in terms of digging deeper into controlled vocabularies and unique identifiers, or also in looking at the different aspects of environmental health (e.g. mosquito monitoring fields would be quite different from water quality ones).
I then thought through our work on the Mosquito Monitoring module of the Atlas of Environmental Health. The Atlas allows Environmental Health officers to go out into the environment, and monitor the populations and species diversity of mosquitoes, including capturing them in traps. The mosquitoes can be then taken to a lab, identified to species level and they can also be tested to see if they carry diseases that will impact on people’s health. From this information, then the Environmental Health officer can determine the best course of action to take to control the mosquito populations in the environment.
At a very simplistic level, this simple workflow got me thinking of Environmental Health” as a combination of the two domains – “Environment” and “Health”. In one of my whiteboard sessions, I ended up drawing a Venn diagram that got me thinking… there must be plenty of data standards within each of these areas that I could potentially point to and use.
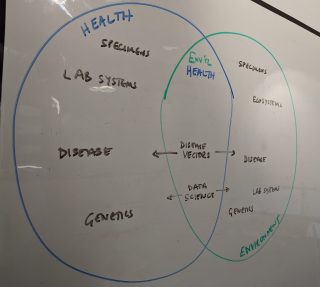
Indeed, for both of these domains, there are a number of existing data standards that can potentially be used to bootstrap the development of new data standards. As a rough first pass, here’s some of the potential standards from the disciplines of “Environment” and “Health” that could be of use… it’s by no means exhaustive, but there are a range of different ways to capitalise on this information.
| Standard | Environment | Health |
|---|---|---|
| Metadata Standards | Ecological Markup Language | Metadata Online Registry |
| Data Standards | Life Science Identifiers
International Union for the Conservation of Nature Conservation Status |
Pathology and Laboratory Medicine Technical Framework
International Classification of Diseases |
| Data Exchange Standards | Darwin Core
Herbarium Information Standards and Protocols for the Interchange of Data (HISPID v.5) |
Health Level Seven |
I’m sure there are other standards out there that I’ve missed, but it seems to me that there is still a fair bit of work still needed to put together a consolidated set of standards for the Environmental Health area, that matches the needs across the various parts of the field.
I wanted to also be clear that I’m not advocating that everyone needs to use the same system or product, which is often confused with using the same data standard. The two should be separate so that there can be improvements, contention, and competition so that these systems and products improve. Otherwise, they will stagnate, especially under a monopoly arrangement when one product is prescribed for use. The key is that all the different systems should use the same data standards, or support the use of the same data exchange standards to ensure data can flow between systems.
If the same data standard was under the hood of the various systems, authorities would be able to readily respond to incidents in a much faster turnaround time. As a result, the world might just be a little bit better…
If you can think of other standards that we should consider (or you know of some that I just couldn’t find), then please drop me a line, or start a conversation on Facebook, Twitter or LinkedIn. I’d like to hear what you think, and how we can compile more resources on this!
Piers
Comments are closed.