Our lives are filled with, (and to a degree, controlled by), information flows. You might start your day by checking in on social media or the news, checking the weather or looking at your calendar to plan your day. You might decide that, although it would be quicker by train, you will catch a bus because the stop is close to a cafe you like that is having a special. Those interactions similarly record information about you. Your preferences, location and habits will (for many of us) be getting recorded by search engines and our phones themselves. If we think of data as static facts, then information, by comparison, is data that is informed by its associations, human assumptions and communication. Typically, machines are great at managing, storing and querying data, but there are challenges once you start trying to use that data as information. For that, machines need to be able to interpret connections between data.
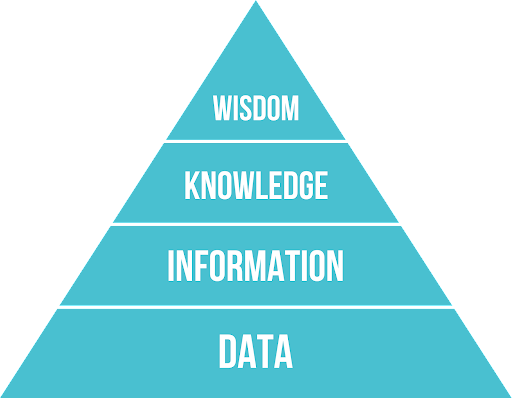
Human intuition is one of the most mysterious and powerful tools our minds have. While I acknowledge the attractiveness of a mysterious and powerful magical ‘sense’, I have always believed intuition is informed by subconscious connections our minds can make; those ‘leaps’ we make, using experience and our knowledge of the likely context of a situation. What if we could provide information to machines in a way that allowed them to understand ‘context’? The more we can build this into our data storage and procedures, the more value can be gained from it, as described by the Data, Information, Knowledge, Wisdom, (DIKW) pyramid.
{kind=link}
Tim Berners-Lee (the computer scientist known for inventing the World Wide Web) created the concept of a “Semantic Web’, which aims to make Internet data machine-readable. The Semantic Web lets us write rules for how machines can handle data contextually, as ‘Linked Data’, allowing our queries to become far closer to the informed, intuitive connections that can be made by the human mind. This allows for ‘semantic queries’, queries for the retrieval of data with consideration of the context and associations applied to it. As a global society, we collect and collate information about all sorts of weird and wonderful things. Quite often, this information is incredibly valuable, but with so much of it dispersed, not necessarily connected to its context, we lose some of the value in how it can be accessed and queried. This also raises Linked Open Data, another concept I am hoping to discuss in later blogs.
What if your Uncle Bob’s slightly obsessive compilation recording the unusual birds in his backyard could be queried by citizen science efforts in his area to identify and protect a rare species? If both Uncle Bob and the citizen scientists connect the ‘rare bird’ to a recognised and authoritative linked data source on it and make their information available, then those records CAN be connected.
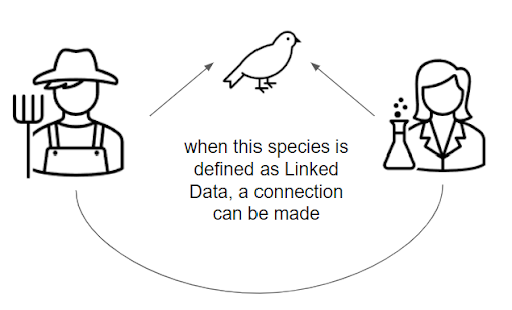
There are a lot of technical tools, technologies and standards in this space, and I am not the right person to break them down in detail (there are also plenty of resources available online). What I would like you to do is consider your own data. If you collect information about something (anything, really), think about how it might be used by others if it could be truly understood by them. What information do you know is out there that you need, but you know is partially obscured by its storage as flat documents, with no context applied?
There are a lot of different concepts, and I love thinking about the opportunities of Linked Data, so we could be here a while if I get started. But I will defer to some of our more technical team, and ask them to expand on these topics again in the future with their expert knowledge. In the meantime, if you do have any interesting data you would like to investigate better ways of querying, feel free to reach out via email or connect with us on Facebook, Twitter or LinkedIn.
Sophie
Comments are closed.