Since our last blog in May, Ben, Kehan and myself have been working with the team at the Western Australian (WA) Museum to finalise finalising the building of the new Collection Management Information System (CMIS), based on the open source CollectiveAccess software.
As a result, we have just reached a milestone in the project, delivering the production instance of the new CMIS!
This is a milestone in the delivery of the new CMIS for the Museum, but it doesn’t mean we now walk away from the project. Instead, we are now working with the team on two new projects, providing technical support and providing rollout support. But what have we been doing since May?
Data, data, data, data, data, data, data. And data.
There has been a lot of ongoing work (mainly by Kehan, supported by Evan and the rest of the database team at the WA Museum) in taking the data from each of the Museum’s current collections data set (as per our May blog), including data from other collection systems, Microsoft Access databases, FileMaker Pro data files, Microsoft Works Databases and Excel spreadsheets and building mappings to bring that data into the staging instance of CollectiveAccess.
We’ve then done some preliminary testing on it, and we’ve been running the mapping scripts to bring the data into the production server we now have running. These scripts take a fair while due to the complexity of the mappings, as well as the number of records being brought in.
Developing, documenting and testing
Development has been, well, an “interesting” experience for all involved.
We have written before about the lack of unit testing in CollectiveAccess, which has been something I know has been frustrating at times to the whole team – but we’ve also been working on that where we can. The development has been a great test of how open source software truly works and the team at Whirl-i-gig have been great in supporting both us at Gaia Resources and the WA Museum here – the time zone difference has played well and truly into our favour, with updates happening while we sleep – although, Seth, we have been wondering when you sleep? In any case, there’s been a lot of co-operation in terms of the development, and the rewards are coming from that.
In terms of documentation, we have been creating an internal wiki (based on the open source Media Wiki) that contains a range of customised “how to” details for each Collection. Obviously there are similarities about how different departments work on particular things, and where possible we’ve written more generic documentation. But the documentation is arrayed by Collection, as well as by subject. Of course, as it’s a wiki, we’ll also be able to keep it up to date and re-use it as we go.
Finally, over the last few months, we’ve also been writing very rudimentary Selenium scripts for testing. Selenium is another open source tool, which has been really useful in keeping an eye on the system, it’s performance and stability along the way. A few times these tests have picked up issues (it takes about half an hour to run through them) that we have been able to identify the root cause for and prepare the system for, prior to the finalisation of the build stage of the project. It’s no substitute for unit tests, but it’s a step in the right direction.
Contributing back
Along the way, the team have been working on functionality that we’ve been committing back into the main CollectiveAccess codebase, all of which is available via GitHub. This has included:
- Enhancements to the data importer,
- Bug fixes to many components of the system,
- Adding the ability to update installation profiles,
- The new Relationship Generator plugin,
- Enhanced LDAP (ActiveDirectory) integration,
- Redirect users to requested page after login,
- Improved documentation,
- Integration with Travis Continuous Integration,
- Adding Australian States to user interface lookups,
- Australian translation of the user interface (not into Strine, though), and
- Adding Australian date format.
We have been using what we have discovered has been called the ‘Github Flow’ workflow for developing, reviewing and merging changes into the project mainline. This helps with maintaining a stable, always deployable branch with feature branches that get merged into it via GitHub pull requests.
To see some of these in action, Kehan recommends that you investigate the Pull Requests in the CollectiveAccess main repository via this URL:
Additionally, all of the WAM specific changes are available on the WAM fork on GitHub, and these are open source and available for others to adopt. This is available at:
https://github.com/wamuseum/providence
You can also see how much is going on in the CollectiveAccess GitHub repository through interfaces like the graphing interface, which tells a story of how busy everyone is on the codebase (Ben and Kehan are now committers #6 and #8!).
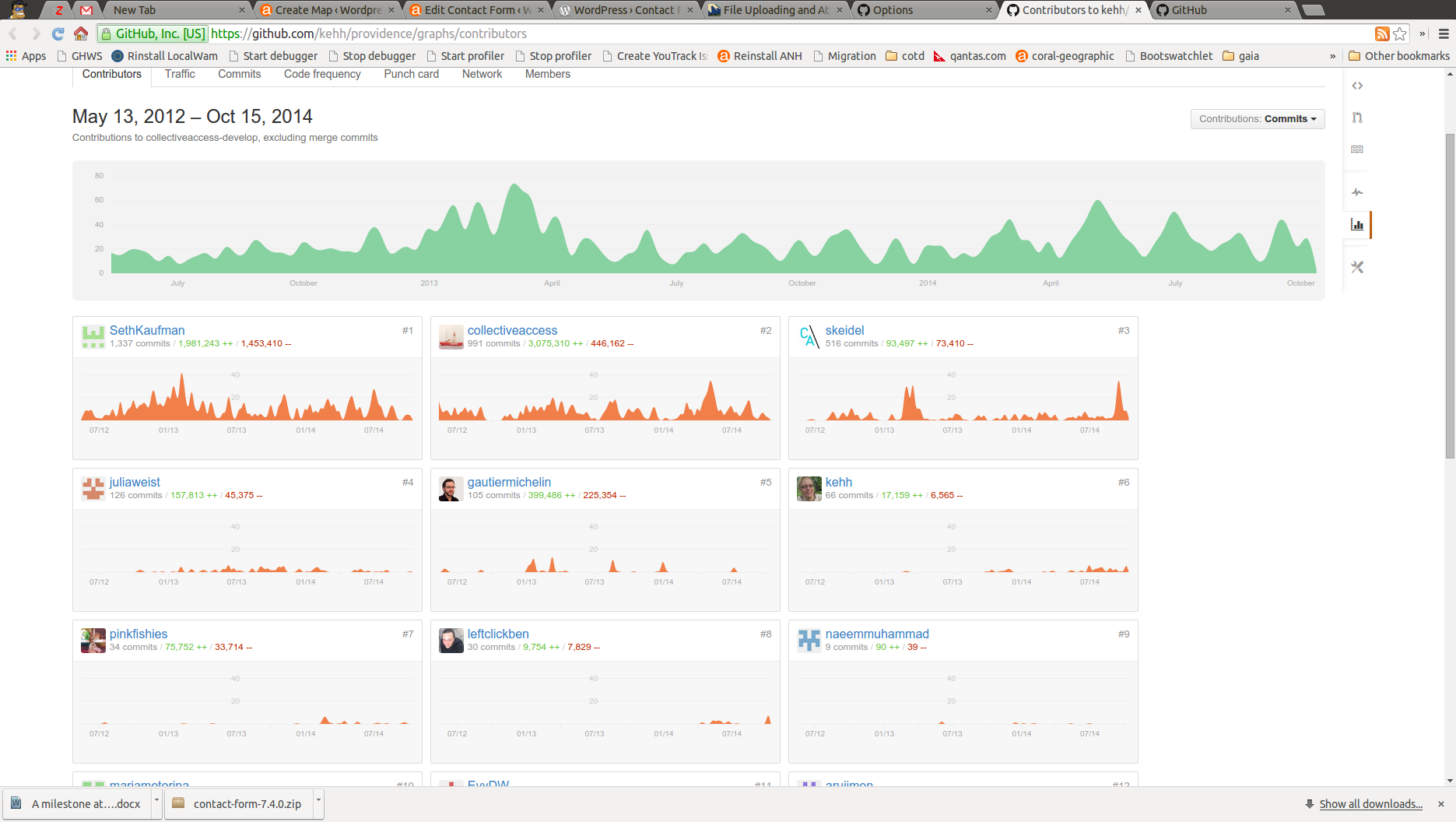 The Contributors for CollectiveAccess on GitHub (click to enlarge)
The Contributors for CollectiveAccess on GitHub (click to enlarge)
Kehan and Ben have also released a bunch of development helper scripts available for others to use and modify, which you can find in the CMIS-tools repository, located at:
https://github.com/wamuseum/cmis-tools
We’ve been working closely with the WA Museum team throughout this process as well – as a great example, Danny developed the WA Museum ‘skin’ for CollectiveAccess and our team merged it into the WA Museum fork.
I’ve already mentioned that we’ve developed a great working relationship with the team at Whirl-i-gig (who manage the CollectiveAccess repository), and they’ve been great at being responsive and flexible, and we’ve gained a lot from this process of contributing back to CollectiveAccess in return. True open source collaboration at its best.
This will also benefit the broader community – already there have been a number of institutions asking for us to work with them on implementing CollectiveAccess across Australia, based on the success of the WA Museum implementation to date.
Where to next?
So, we’ve been preparing what we now call the “building blocks” for this next phase of the WA Museum CMIS rollout via the production instance and this week kicked off the first team meeting for the rollout, consisting of the WA Museum’s Digital team, the Database team and a few of us from Gaia Resources (Kehan, Ben, myself and now with Alex brought into the project). We all think the end result is a great outcome.
A sneak preview of the new WA Museum skin for CollectiveAccess
Our focus now shifts to two main things – the technical support team needs to embed the skills and knowledge within the WA Museum to be able to be self-sufficient and manage CollectiveAccess into the future, and the rollout team needs to work with the curators and other staff to make sure that it can perform as they need to, and that they are trained in the system itself.
I wrote back in May that it was really exciting to see it all coming together, but there was no way I was really prepared for how readily and rapidly it all came together in the last few months, thanks to stellar work by the whole team behind the project, from my own team at Gaia Resources as well as the WA Museum team, and of course, the sleepless people at Whirl-i-gig.
Piers
Drop me a comment below, or get in touch via Twitter, Linkedin or Facebook.
Comments are closed.