The Northern Territory Government is one of the many organisations that we help solve environmental technology challenges with. We’ve been having interesting conversations with the Flora and Fauna team at the Department of Environment, Parks and Water Security (DEPWS) for a while now, but recently we undertook a proof-of-concept project with them around streamlining the field survey data collection efforts with Artificial Intelligence (AI).
This proof-of-concept project came about from a chance discussion in a meeting around biological data and data standards, where we were talking about hard copy data capture forms and how time-consuming it was to transcribe them into a database. We have been working for some time on an AI service offering around transcription and so, we proposed to trial our Clio system to see if it could help solve the transcription problem for the Flora and Fauna team.
Imagine a bird survey containing several small plots at a site near Alice Springs, and over the course of 4-5 days the field scientist records the birds they observe or hear and other details. Information about each bird – such as its gender and age – is collected, if possible, to help in modelling population trends and understanding ecological processes. Once the field work is done, the notes are copied into a standard survey form.
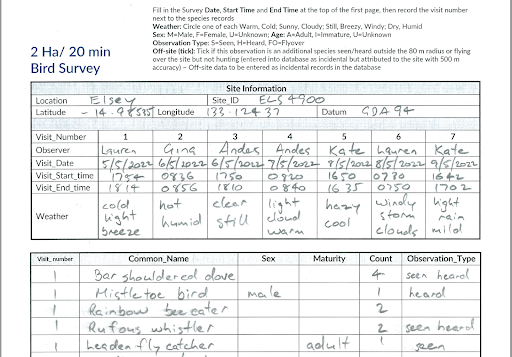
Input bird survey form
The hard copy forms contain a bunch of site information (e.g. siteID, surveyor’s name, coordinates, plot size, land descriptions etc.) and a number of visits at different times, with where observations of species are recorded as a list of occurrences. Due to the complexity and rapid data collection techniques in the field, these surveys continue to be done with pen and paper. The forms build up across a team of field staff over the course of a year, and this then creates a significant backlog of time-consuming manual transcription work.
That’s where our team comes in. Gail Wittich is a Data Scientist at Gaia Resources and Hayden Richards is one of our Software Engineers who jumped at the chance to work on this proof-of-concept project. The outcome we were chasing was to see if we could significantly reduce that manual data entry time. I spoke to Gail about how she and Hayden tackled the challenge.
Were you just able to feed the scanned field survey forms in, and get the data out?
Not quite, but that was the general idea. We were able to save a significant amount of human processing time by first modifying the design of the survey form, and then introducing the AI algorithms to process the scans. Specifically, this uses Handwritten Character Recognition to read the forms and output a machine-readable file. The raw outputs from Clio also required some post-processing to fix some common spelling and format errors; but from there it was ready to have minor edits and curation performed by a human, before being ready as tabular data to import into the database.
What does the processing approach look like?
The nt-birds-survey-tool is a proof-of-concept Python script for performing Clio text recognition on scanned PDFs, post-processing raw results and outputting tabular data as CSV files. We utilise cloud storage, tools and services from Amazon Web Services (AWS) to help bring this service together.

High level Technical Overview
The wonderful thing is that Clio gives a clear indication as to how well it is able to read each component of text, in the form of a Confidence Level (percentage) which can then be viewed chromatically to draw your attention to the problem areas for corrections. It also recognises form field and tabular information, and can export that into sensible data as rows and columns in a spreadsheet.
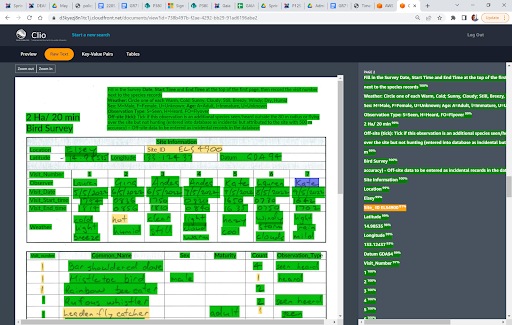
Clio prototype interface
What are some of the technical challenges you’ve come across?
AI has come a very long way in the last 20 years, and it is a rapidly evolving space; but for our line of work we are not talking about robots and algorithms that can pass the Turing test. For us, it comes down to helping scientists and researchers achieve time efficiencies and savings that they can apply to doing more good environmental work. As you can imagine with bird surveys, a person’s handwriting is not at its best when the person is writing on a clipboard or notepad and moving swiftly around in variable weather conditions. Complimenting the Clio raw result with standard post-processing techniques improves results significantly. It’s still tough for a machine to correctly read a 2 when it is written like a Z, for instance, but when you know the data is referring to a count of birds, you can be sure it is a 2. Or an S is a 5, and an I is a 1, and so on.
Initially, Clio recognition was as low as 73% (73% of information on a form was correctly transcribed). In many cases this was just one or two letter differences or a few numbers interpreted as letters. With the form design and a range of post-processing corrections like the ones above, we were able to increase accuracy to between 93% and 99%. We know that a successful implementation also requires a bit of training and reinforcement for field staff in how to use the form, but we were really pleased with those results.
Why not just collect the data with a mobile app?
While we are big supporters of mobile apps and field technology solutions in the right situations, Clio is designed to support scanned content – current or historical. Just because we have the ability to build apps, doesn’t mean that every challenge will be solved by having one. Clio is ideal for the situations when people get back to basics – and use pencil on paper.
Why do you think this work is important?
Biodiversity data helps to answer important research questions and inform decisions on a variety of subjects, including: urban and rural development impacts, climate change and how it affects habitat and species populations and migration patterns. I work mainly with the data, but I can definitely see how we need reliable and efficient methods to generate and aggregate consistent, standardised data of this type to support research into those areas.
Where to from here?
We have proven that with some minimal redesign of form inputs, we can use this solution to get highly accurate transcriptions from these handwritten survey forms. We know it is going to save time, but this isn’t just about birds. There are many different types of flora and fauna surveys out there, including vegetation, mammals, reptiles, invertebrates and more – and several survey techniques and guidelines that define best practice in this space. We are concentrating on the survey forms, and I think the intent is that we can realise those time savings on many of those different types by following a similar process. We do need to run more tests and measure manual entry times for comparison. However, even if this saves 30 minutes in data entry per survey (not really a stretch when you think about it), for every thousand of these forms the payoff is 500 hours in time savings.
It’s really exciting to be undertaking proof-of-concepts like this one that allow us to leverage AI to help clients turn their scanned content into rich, standardised and reusable biodiversity data. We’ll have another blog a bit later to tell you about another Clio proof of concept project we’ve undertaken in the archives world – so stay tuned!
If you’ve got data in a hard copy format that you need transcribed, then reach out to us and let’s see how we can help you solve your problems. In the meantime, if you’d like to know more, start a conversation on our social media platforms – Twitter, LinkedIn or Facebook or send me an email.
Chris
Comments are closed.