In a blog from last month I wrote about the good work that’s already been done within individual biodiversity knowledge domains. But what are the future needs of scientists, ecological consultants, land managers, environmental agencies working across those domains? To enable significant and effective conservation and land management in a changing landscape, biodiversity data needs to be integrated and reliably shared on a massive scale.
There are a range of use cases that we can expect will be relevant for the future, like:
- what species and ecological communities occur in this parcel of land and how complete and reliable are those data?
- how representative is our biodiversity knowledge in any location and across the State?
- where are all the long-term survey sites and what can they tell us about the changes in biodiversity and ecosystem health over time?
- what are the ecological constraints on any new land use proposals?
What data do bioinformaticians need to provide to clients and decision-makers to meet these use cases? As ever – it starts with ‘what and where’ in a variety of ways:
- what populations, species, assemblages, ecosystems, and where do they occur;
- what are the risks and threatening processes to be considered and where are those risks at there highest;
- what are the gaps in our knowledge and where are the skills and resources required to fill those gaps.
One example of the types of ‘what and where’ that will be asked can be shown in some of my research and development projects that I have been working on over the years, like this example for the Western Australian Herbarium collections, illustrated below.
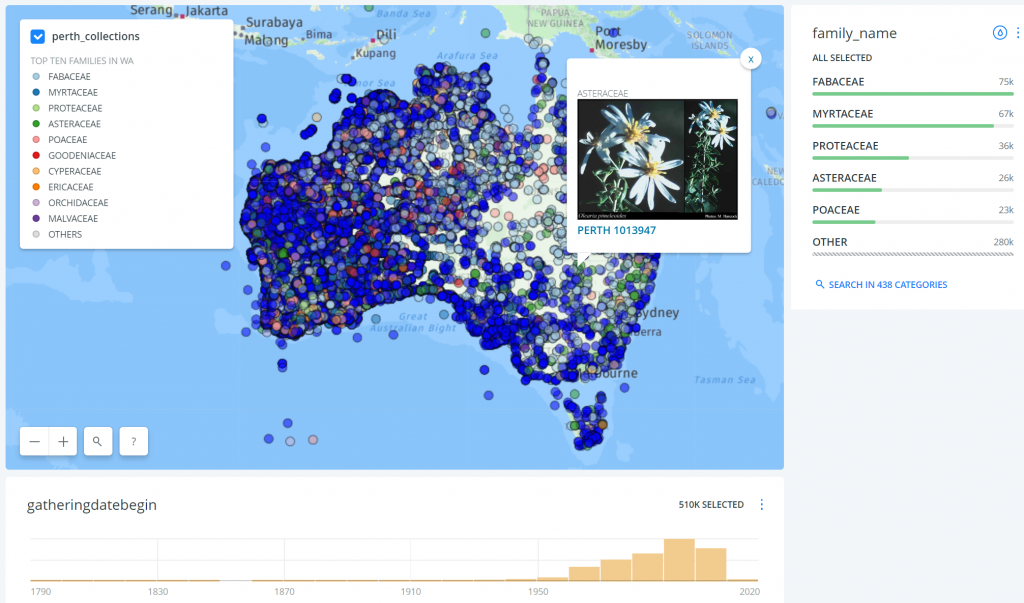
This web tool displays c.510,000 geocoded specimen records from the Western Australian Herbarium faceted
by 438 plant families, along with a summary of their collection dates by decade and pop-up links to FloraBase
While it is currently possible to interrogate individual systems (as above), or DBCA’s NatureMap, or utilise national data aggregators such as the Atlas of Living Australia, to develop a comprehensive approach within the State we will, at a minimum, require:
- layers of web services implemented on top of existing data systems in order to make core data available across domains,
- a portal to visualise the available data with ‘dashboard features’ to quickly provide metrics on the biodiversity of an area and representativeness / completeness of that data,
- a long-term plan for building infrastructure and connectivity with a strategic plan for increasing and improving the data in the system, and the systems themselves.
The first steps will potentially be:
- a stocktake of all the relevant information systems;
- detailed analysis of those system schemas and the applicable data standards in use;
- modelling of the data interactions to flexibly deliver the key use case functionality;
- implementation of any required changes to individual data systems to enable full participation in the new system;
- identification of system dependencies or weaknesses to ensure each contributing information system can continue to reliably deliver.
Demand for biodiversity knowledge is increasing. There are many projects aiming to deliver new information — effective and efficient coordination across all stakeholders will be key. If you’d like to talk further about future initiatives, contacted me directly via email (alex.chapman@gaiaresources.com.au), or through Facebook, Twitter or LinkedIn.
Alex
Don’t forget quality!