In the 18 years since our inception, we’ve always worked with, on and around biodiversity data. You will have seen some of Chris’ recent thoughts on this area in our last blog on spatial data in biodversity. For this blog, we thought we’d turn to looking at the various data standards that are used in biodiversity data, and how our approach to them has changed over time.
We’ve had a lot of interaction with standards bodies – like Biodiversity Information Standards (TDWG) along the way, and even have been involved in the setting up and development of these data standards. And we’ve done a lot of work with clients, especially in the mining industry, around helping them to manage their data against data standards, like our work with the Department of Water and Environmental Regulation, Rio Tinto or Mineral Resources.
There are a range of standards for different aspects of biodiversity data, and some of the ones we’ve worked with most recently include:
- Darwin Core – a standard for sharing occurrence level biodiversity data,
- Australian Biodiversity Information Standard (ABIS) – a standard that is built on a Resource Description Framework graph to cover a broad range of aspects of ecological surveys, and
- VegX – a data standard designed around sharing plot-based vegetation data.
These data standards each have some core reason for their original development. For example, Darwin core was developed to facilitate the sharing of occurrence data between organisations, while ABIS came from the Terrestrial Ecosystem Research Network (TERNs) Ausplots systematic survey protocols. Along the way these data standards get enlarged, changed, but always show their roots.
This means that you can’t simply pick up a biodiversity standard and say “right, I’ll use this for the gathering of information for my ecological survey I’m doing next week” and it will contain all the fields that you will need for your work.
Not that we’d encourage that sort of thinking, because each survey that is undertaken will have a different purpose. You might be doing a survey that looks at mangrove health, so you’re interested in the species and the canopy cover as the main indicator of that. Or, in a bat survey, you might be seeing how many individuals of a threatened species are in an old adit that is near to a drilling rig, so that you can see if that drilling has an impact on their numbers. Or, you might be traversing the slopes of a potential mine site looking for threatened flora species. Or, you might be helping collect specimens for researchers, and you’re measuring the weights and lengths in the field.
Sorry, that was a bit of a trip down memory lane for me – those are all examples of surveys I have been involved in – which all started from my very first survey, pictured below.

That yellow hat became a standard accessory for my field work – and boy did it get a workout
Ever since that first survey, I’ve been thinking hard about how the heck do we actually manage the data that we collect in the field, and preserve it.
Each of those types of surveys I mentioned above have things in common, but also some key differences. While all of them have species information, location and those sorts of information that easily fits in a data standard like Darwin Core, some of them also have other fields that don’t have placeholders in that data standard (canopy cover, for example).
In the past, what has been done is that the fields that don’t fit simply get discarded, and you end up losing the richness of the data that you have collected in the field. So, while you might have the data stored locally somewhere and somehow, when you’ve parsed the data into the standard, you effectively lose that data when you provide it to someone else. That’s always seemed like a really big loss to me – there’s so much effort to collect that data, and then it’s suddenly discarded.
Thanks to a lot of thinking on this from our colleague and friend Paul Gioia (who we still miss a great deal since he passed away in 2019), we came up with the way in which the BioSys system works – you don’t force people to remove those fields, but instead you ask them to provide every field they collect and then match the fields to those in a data standard. From Paul’s initial inspiration, we have evolved this into a three step approach:
- Step 1: Map your data to a standard: You take any biological dataset and match the fields within it against a chosen data standard, as many as you can – and then store those matches (which we call mappings) along with the dataset,
- Step 2: Map your standards against each other: For your system, you can then map fields between different applicable data standards that you choose to support in the system against each other, and then
- Step 3: Output in any standard you have chosen: You can now export out the original dataset from the system against any of the data standards that you have chosen to support.
A graphical representation of these three steps is shown below.
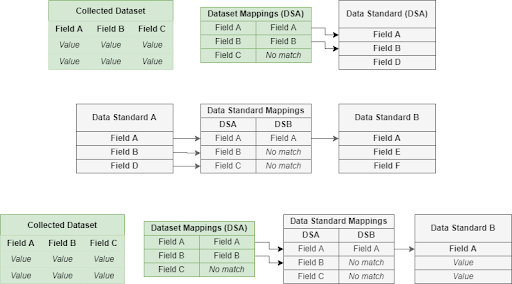
The three step process shown above is something we’ve been working on across multiple projects, starting from BioSys and moving through to more recent projects
What this approach does is mean that we are future proofing biodiversity data, and a big part of the evolution we’ve applied has come from our work in the Collections and Archives area – where we want to make sure that data is preserved forever. We want to bring this idea across to the biodiversity area and make sure this data persists there, too.
Specifically, this approach delivers the ability to:
- Store all the fields that you are provided from a data supplier – even if they don’t currently match a data standard,
- Update the data standards over time without impacting the data – you can add fields and retrospectively introspect the datasets that are in the system to see if you can do more mappings and then have a richer dataset, and
- Completely change the data standards over time – you can replace the data standards and the underlying data is not affected, you effectively just re-do the mappings.
This approach turns traditional biodiversity storage and aggregation into something that is more akin to an archive – it makes it more future proof and enables the richness of the captured and supplied data to be truly kept for the future.
This is something that has been a bit of a passion project for us, mainly because we’re seeing the use of data standards inadvertently mean that people throw away valuable data that should also be preserved. If we’re going to make the world a better place, tossing away data that documents our environment is not going to be the way to do that – hence the title of this blog which is all about responsibility.
We’ll continue to be working with the biodiversity community to deliver ways to implement this sort of responsible implementation of data standards wherever we can. If you’d like to know more, then start a conversation on our social media platforms – Twitter, LinkedIn or Facebook, or drop me an email.
Piers
Comments are closed.