Artificial Intelligence (AI) has been overhyped, but here at Gaia Resources we’ve been working with AI for some time - over five years in fact (as highlighted from our recent #ThrowbackThursday post on our social media platforms). While there is a fair bit of talk about the ‘AI bubble is about to burst’ lately, there are things that AI can be good for - as long as it is deployed somewhere that makes sense and is well chaperoned.
Recently the National Archives of Australia put out a Request for Information to help find out how AI could assist with four areas of interest that are well laid out in an IT News article from last year, which we quote here:
The first is transcription and involves rendering digital records into a text file format, which could improve searchability, translation and accessibility to the archives.
Description of data, relating to creating and updating associated metadata for records, was also of interest, and could include tools to assist with summaries, tagging, biometric recognition, image detection and other form fields.
A third area titled "access examination" relates to analysing the contents of data against exemption categories outlined in the Archives Act 1983 (Cth). This may include tools to assist with peer reviewing, guardrail assistance, keyword detection and synthesis from multiple created documents.
Finally, the Archives is interested in what impact AI could have on ‘search and discovery’ of its digital collection of media.
So, putting some of our previous work and experience into action, we created the Metadata Annotation and Transcription Engine - MATE - to demonstrate how AI can be used to address these challenges.
First up we started with some specific architectural decisions, and the first was the most important: we have to make people the heart of the system - and specifically archivists. MATE was designed from the ground up to supplement the existing archival teams and empower them to achieve more, rather than replacing their expertise, passion and skills.
The other architectural decision was: make it open but secure. So we looked at operationalising open source models within a secure cloud environment where there’s no data leakage. While we haven’t done the full set of security hardening at this stage - it is a prototype after all - we have it ready for that in the future.
And so, in just three weeks, MATE was born.
MATE consists of a range of different functional components that are outlined in the diagram below, but broadly speaking this includes:
- The base system - where there are process queues implemented that assist with the management of tasks throughout the whole system, as well as other components such as the Quality Assurance agent that people interact with,
- The Transcription and Description agents - which includes three agents; vision (for handling transcription from images), speech-to-text (to handle transcription from videos) and a description agent (to describe the contents),
- The Access Examination agents - one which looks at the access examination and the second that looks at any sensitivity in the data (culturally and otherwise), and
- The Search & Discover aspect - where there’s a load of APIs that deliver the right functionality to other public front end sites.
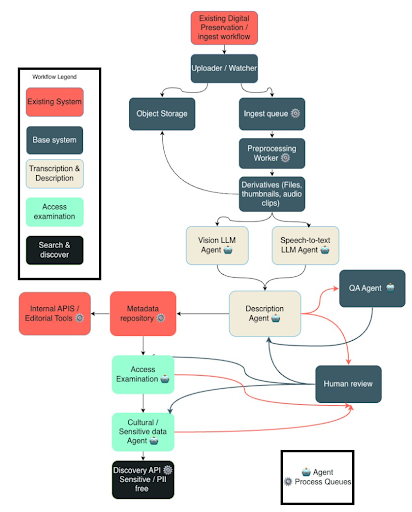
This all has places where it can fit into existing workflows; such as existing pipelines for ingestion or digital preservation, or existing Archival Management Systems (i.e. metadata repositories). This is important - making sure that this whole system isn’t a major disruption to existing systems, but integrates with what you already have.
MATE is web-based: there is no need to install anything. Access is controlled through the authorisation layers, and once in, the way that MATE works in this prototype is pretty simple:
- You load the file into the interface through a simple drag and drop interface - files across a range of formats including images, documents, and videos up to 4GB can be loaded into the system (in the future, this would involve plugging this directly into an existing ingestion workflow),
- The system processes the files and then presents them back into a gallery for review. The system presents all the information that has been collated from the various agents,
- The “human in the loop” starts next - you can review, look at data, and using the QA agent can actually chat through a reingestion process with the system, and repeat this process until you’re happy with the results and approve the ingestion - with a final option to add notes to the item and save those with the object’s metadata,
- The process also then runs through access examination - in this case we implemented the NAA Access Examination Policy to so that information meets those criteria is flagged and returns information about what should happen to this object - should it be withheld or pushed into the public domain, and
- Then once this is complete the object can be approved and pushed into the search and discovery portal, where you can use natural language processing to search and discover things about the object.

Through this type of process, what MATE does is streamline the work that archivists do, doing a first cut of the transcription, description and access examination. These first cuts are then provided to someone to review, and through the workflow queues that are in the system, can ensure that these reviews can be managed over time - be that through picking it up later when you have time, or handing that to other people to finish off.
So far we’ve been pretty happy with MATE’s responses to some of the challenges and the sample data that we’ve had. What we’re currently doing is taking some open records from different archival agencies and testing it against what is in the catalogues for those records, so that we can see how accurate the system is. It’s done a fine job so far for the test data we’ve been using and the internal measures of accuracy (a great way to do some filtering of your backlog - show me things that the system thinks it’s done well, or done poorly) are holding up to scrutiny. We had a great one the other day of a video that was showing just a 40% confidence value - turns out the video file actually was missing an audio track, so the system outlined that it contained no transcribed content - but never could anyway.
We do love trying out new and innovative things. From our previous work with AI and fish, or transcription from field sheets and archives, we now have something that is a little more holistic across a very real world problem - helping archivists to maintain their oversight and bring their knowledge to the table, but through a simple to use interface that can increase their productivity without compromising on the quality of their archive.
MATE is in its early stages and we’re looking for more ways to test and build upon it - so if you are interested and want to have a look at the system and how it works, then contact either myself or Jarrad Lawrence, our Business Development Manager, and we’ll arrange a demonstration of the system - and leave you with a login to play with your new MATE and see how it performs.
If you’re interested in meeting MATE or seeing more about the system or how we can help you innovate around your challenges then get in touch via email, or start a conversation with us on our social media channels.
Piers